Find Your Best Model
Model evaluation is more than a single score it’s about comparing models based on your application’s requirements and constraints. Remyx simplifies this process by ranking and evaluating models in context. The MyxBoard acts as a customizable leaderboard, organizing evaluations by your chosen metrics, tasks, and datasets. This helps you explore model performance, trade-offs, and strengths across scenarios.MyxBoard: Model Evaluation Tracker
The MyxBoard organizes model evaluations into groups, making it easy to compare models across datasets and benchmarks. It keeps evaluations structured, reproducible, and shareable, so you can quickly find the best model for your needs.Available Evaluations
MyxMatch:- Custom evaluations tailored to your application’s unique needs.
- Synthesize custom benchmark from sample prompts and/or context about your use-case for LLM-as-a-Judge to assess each model.
- Powered by lighteval, evaluate models using predefined benchmark tasks like TruthfulQA or other industry-standard datasets.
- Compare performance given benchmark specific metrics.
Quickstart
You can quickly create a MyxBoard to track and view multiple evaluation results. It can be created from a list of models or from a Huggingface collection. Here’s an example that launches MyxMatch and Benchmark evaluation jobs for a MyxBoard using the Remyx Python API.Running MyxMatch and Benchmark evaluations
evaluate method will launch the specified evaluation jobs, polling periodically for their completion. Once their status is "COMPLETE", you can fetch the results using myx_board.get_results(). You can expect to see a json including all job results:
Evaluation Results
Viewing and Sharing Your MyxBoard
The MyxBoard will be stored, and all updates will be handled automatically by the Remyx CLI, ensuring your MyxBoards are always up-to-date and easily retrievable. If you created a MyxBoard from a Hugging Face collection, you can also store your results in that collection as a dataset with thepush_to_hf() method.
View Results
Evaluate in the Studio
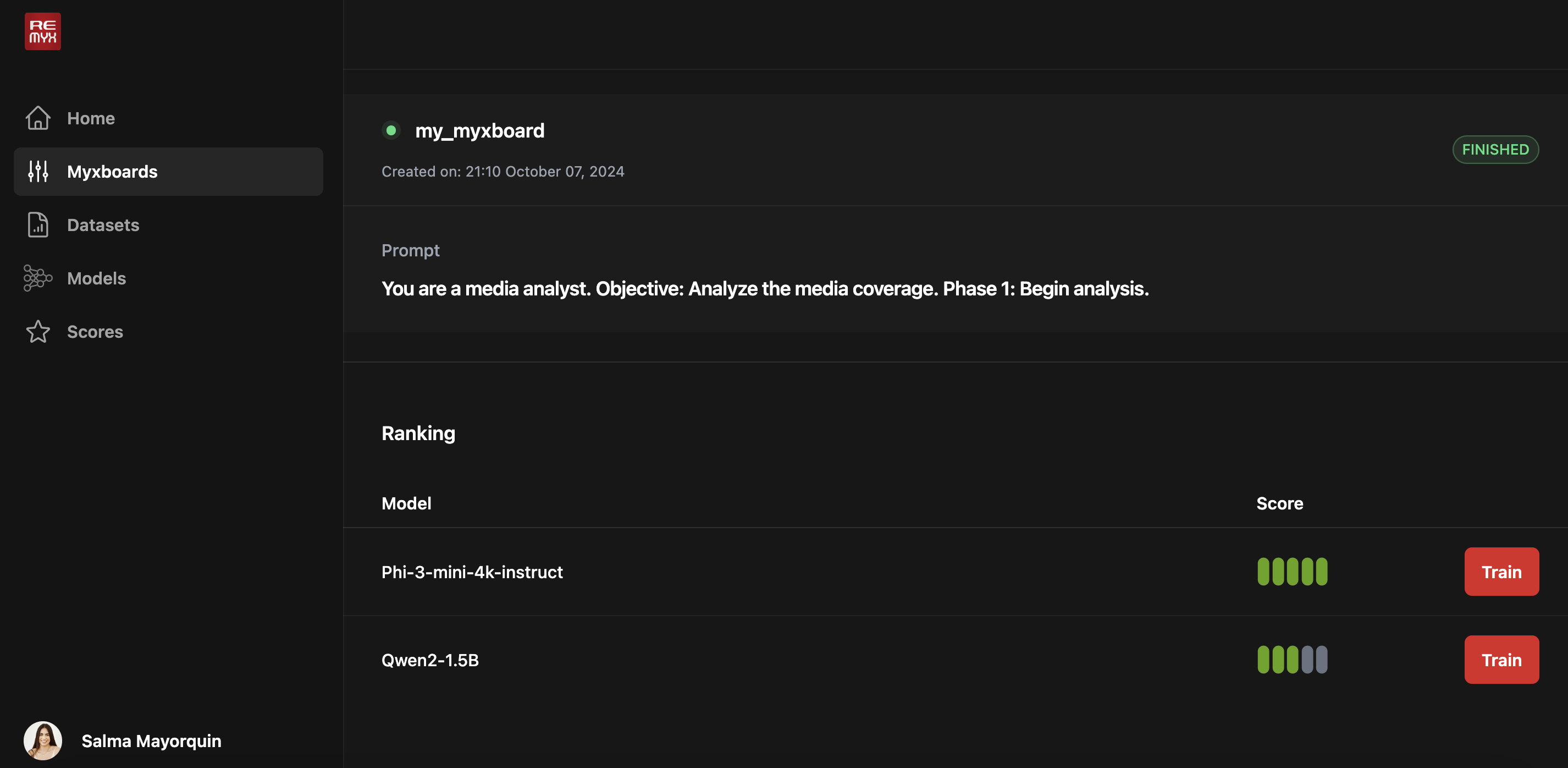
You can find the MyxMatch under the “Explore” section of the home view. Once you’ve clicked into the tool, you can start filling out the name for your matching job. Include a representative sample or prompt in the context box to help source the best model. Optionally, you can click the “Model Selection” dropdown button to select which models you want to compare. By default, all of the available models are chosen.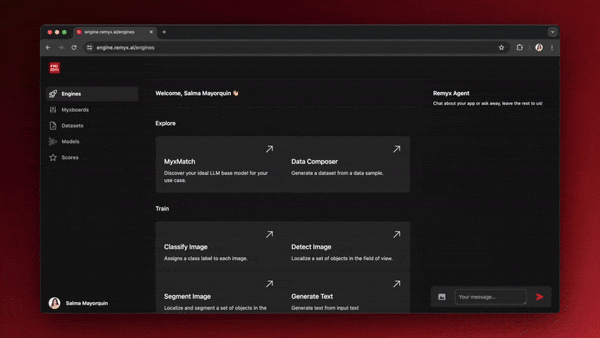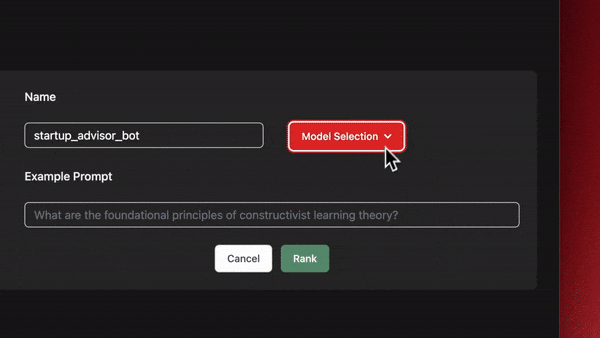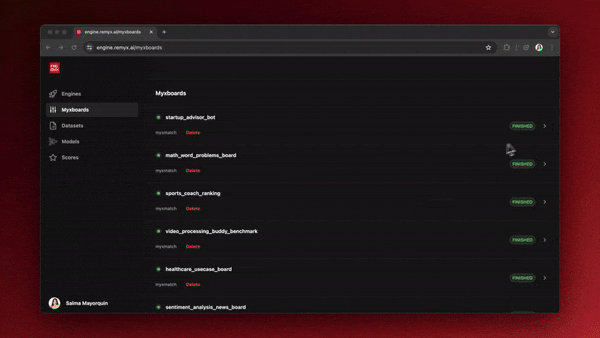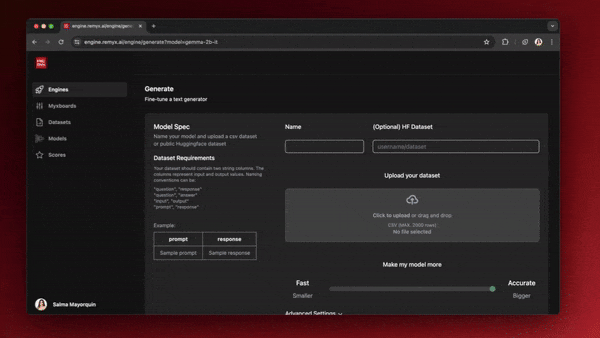 After you’ve clicked “Rank,” you’ll be redirected to the Myxboards view, where you can monitor the progress of your matching job. Once it’s finished, you’ll see a table ranking all selected models, with the top-ranked ones at the top. If you’re ready to move on to the next step and train a model, look for the “Train” button in the last column and click it.
After you’ve clicked “Rank,” you’ll be redirected to the Myxboards view, where you can monitor the progress of your matching job. Once it’s finished, you’ll see a table ranking all selected models, with the top-ranked ones at the top. If you’re ready to move on to the next step and train a model, look for the “Train” button in the last column and click it.
Future Developments
With the MyxBoard, you can customize and streamline the evaluation of models for your specific needs. Whether you’re ranking models based on their alignment to your use case or sharing your results with the broader community, the MyxBoard makes it easy to tailor and track evaluations while adding more context to your ML artifacts, enhancing your experiment workflow. Stay tuned for the next updates to the evaluation features on Remyx, including:- Support for more fine-grained evaluation tasks and model comparison options.
- Expanded evaluation modes, including multimodal and agent-based tests.