This guide will show you how to customize an LLM for your application through fine-tuning. We’ll cover all of the modeling options, data inputs, and what to expect after training is complete.Documentation Index
Fetch the complete documentation index at: https://docs.remyx.ai/llms.txt
Use this file to discover all available pages before exploring further.
You can use the Data Composer tool to generate a dataset if you do not have one. Otherwise, you can format your own according to the specifications below.
1. Via the Experiments Tab
Go to the Experiments tab in the left sidebar and click New Experiment.- Select Model Finetune from the Experiment Type dropdown.
- This will configure a new experiment card where you can configure your model, training strategy, and dataset.
- Drag the card to the Launch column and click the Launch button to run your training job.
- Once the status on the card updates to Complete, move the card to the Ship column to view the results.
2. Via the Home View
From the Studio home screen, scroll to the Train section and select the Train tool.- Select a model type, currently supports fine-tuning LLMs (Text → Text) and VLMs (Image, Text → Text).
- Fill out the configuration form with details like strategy, base model, and dataset source.
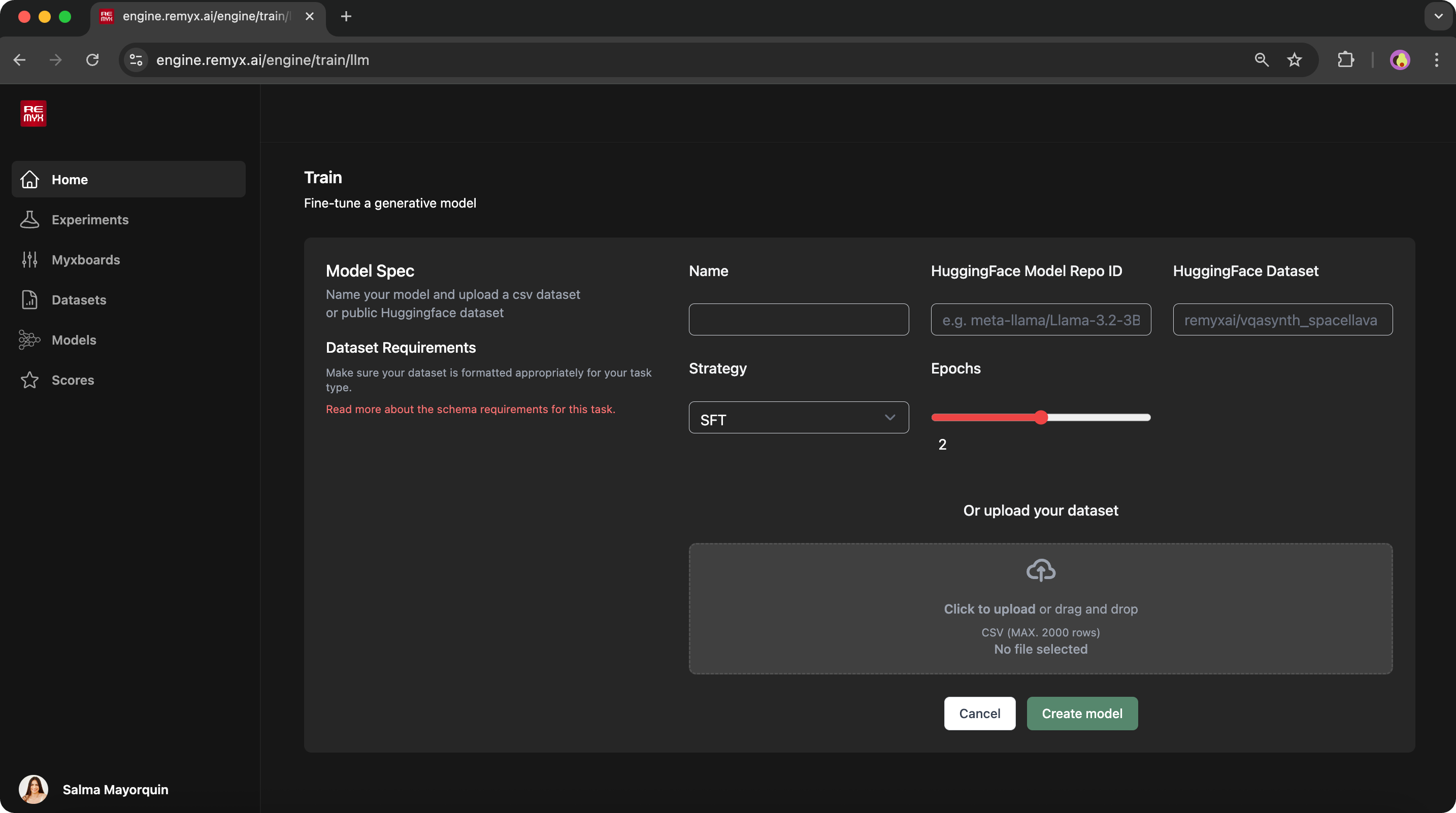
Supported Fine-Tuning Strategies
Remyx supports fine-tuning Large Language Models using parameter-efficient training methods, specifically LoRA (Low-Rank Adaptation). We currently support the following strategies using LoRA:- Supervised Fine-Tuning (SFT) : Provide prompt-response examples to teach ideal behavior.
- Direct Preference Optimization (DPO) : Train with preference pairs to improve model alignment.
Supported Models
The free developer edition of the Remyx Studio supports fine tuning base models up to 7B parameters. See the available models documentation for details on supported model architectures. If you need to train larger models, please reach out!Dataset Requirements
Your dataset must match the required format for the selected strategy. Upload your own file or generate one using Data Composer.SFT Format
| prompt | response |
|---|---|
| What are the benefits of LoRA finetuning? | LoRA allows for efficient parameter updates with reduced memory usage. |
| How does attention work in transformers? | Attention enables models to weigh the importance of each input token in a sequence. |
Required Columns
prompt: A question, prompt, or user utterance.response: The ideal model response to the prompt.
DPO Format
| prompt | chosen | rejected |
|---|---|---|
| How do I deploy a model locally? | You can use the Remyx CLI to launch a local endpoint with the deploy command. | You just run it. It should work fine. |
| What’s the capital of France? | The capital of France is Paris. | I think it’s either Madrid or Rome. |
Required Columns
prompt: A question, prompt, or user utterance.chosen: A high-quality response.rejected: A lower-quality or less preferred response.
Monitoring Progress & Reviewing Results
After submitting a training job:- Track progress under the Models tab in the left sidebar.
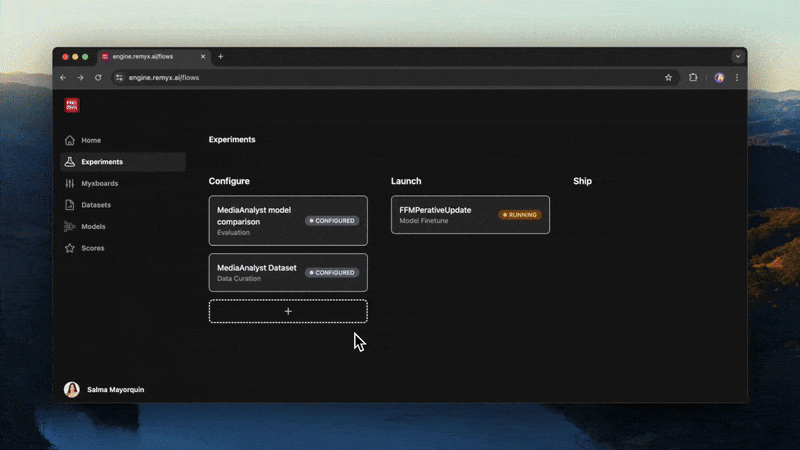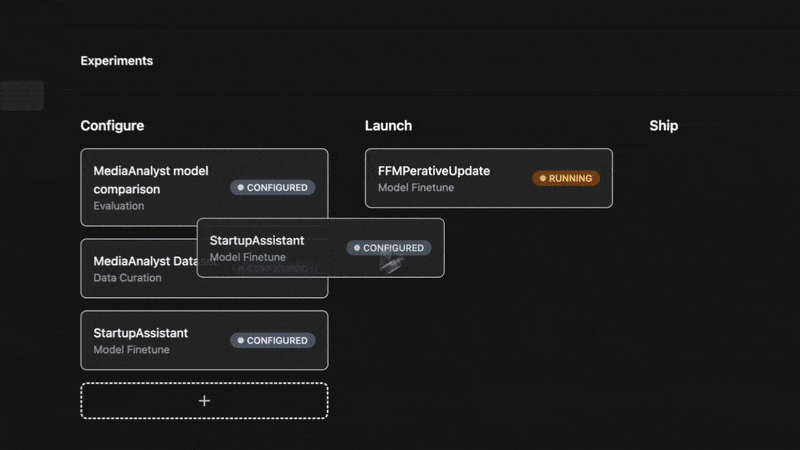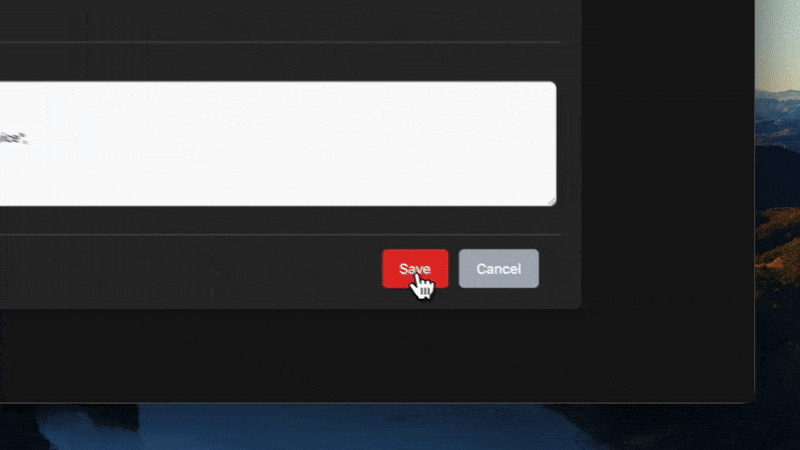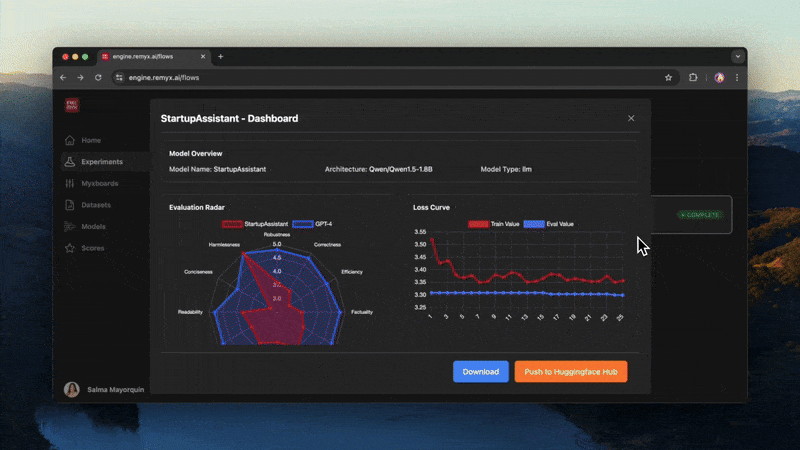
- Once training completes, click your model to open its dashboard:
- View training strategy, architecture, and hyperparameters
- Visualize metrics like loss and accuracy
- Review evaluation outputs
- Test the model in-browser
- Download inference code, export models, or deploy